

El uso de “Data Science” no se trata de hacer modelos matemáticos complicados, no se trata de hacer visualizaciones de información muy robustas o complejas, tampoco se trata de escribir líneas de códigos; “Data Science” se trata de usar datos para crear el mayor impacto posible en las organizaciones. Este impacto puede ser en forma de “insights” o en forma de recomendaciones para la toma de decisiones clave en los negocios u organizaciones.
 Para que una organización pueda alcanzar estos objetivos, es necesario contar con las herramientas que permitan hacer y visualizar estos modelos complicados de los datos o escribir código; pero, como profesional en “Data Science”, el trabajo es esencialmente resolver problemas reales dentro de las organizaciones. Las plataformas de información robusta son necesarias, pero es vital contar con profesionales que usen de la mejor manera esa información en pro de las organizaciones.
Para que una organización pueda alcanzar estos objetivos, es necesario contar con las herramientas que permitan hacer y visualizar estos modelos complicados de los datos o escribir código; pero, como profesional en “Data Science”, el trabajo es esencialmente resolver problemas reales dentro de las organizaciones. Las plataformas de información robusta son necesarias, pero es vital contar con profesionales que usen de la mejor manera esa información en pro de las organizaciones.
Hay muchos conceptos erróneos sobre “Data Science”, especialmente en redes sociales, y la razón probable es que hay una gran falta de alineación entre la definición o creencia popular y lo que en realidad se necesita en la industria.
El término popular de “data mining” fue popularizado en un artículo de 1996 llamado From data mining to knowledge discovery in databases (De la minería de datos al descubrimiento del conocimiento en bases de datos), en el cual se hacía referencia al proceso general de descubrimiento de información útil de datos. En 2001, William S. Cleveland quería llevar la “minería de datos” a otro nivel, combinándola con la informática; básicamente hizo las estadísticas mucho más técnicas, con la firme creencia de que ampliaría las posibilidades de la minería de datos y produciría una fuerza poderosa para la innovación. Hoy vemos que tuvo mucha razón.
 Habiendo aprovechado el poder del cómputo de datos para las estadísticas, extendió el término de “Data Science” al uso que le damos hoy en día. También por aquellos tiempos fue cuando surgió la web 2.0 donde los sitios web ya no solo eran una hoja digital, sino que se habían convertido en un medio para una experiencia compartida entre millones y millones de usuarios en sitios como MySpace en 2003, Facebook en 2004 y YouTube en 2005.
Habiendo aprovechado el poder del cómputo de datos para las estadísticas, extendió el término de “Data Science” al uso que le damos hoy en día. También por aquellos tiempos fue cuando surgió la web 2.0 donde los sitios web ya no solo eran una hoja digital, sino que se habían convertido en un medio para una experiencia compartida entre millones y millones de usuarios en sitios como MySpace en 2003, Facebook en 2004 y YouTube en 2005.
Hoy en día, interactuamos con estos sitios web, lo que significa que contribuimos con la misma red publicando comentarios, fotografías, reseñas de productos o artículos como este, lo cual nos permite dejar nuestra huella en el paisaje digital que llamamos Internet, ayudando a crear y configurar el ecosistema que ahora conocemos, aprovechamos y amamos.
Manejar y administrar todos estos datos se convirtió en una tarea muy compleja de lograr con las tecnologías tradicionales, por eso decimos que la “Big Data” abrió un mundo de posibilidades para encontrar ideas e insights utilizando estos datos, pero a la par, significó que las preguntas más simples de responder requirieran una infraestructura sofisticada solo para respaldar el manejo de tales datos. Por tanto, necesitábamos una tecnología pionera de cómputo paralela, como “MapReduce”, bajo el modelo de implementación Open Source llamado Hadoop, donde Yahoo fue uno de los principales desarrolladores y que fue piedra angular en el proceso y los avances.
El aumento del “Big Data” en 2010 provocó el aumento de la necesidad del uso de “Data Science” para apoyar las necesidades de los negocios de obtener información relevante con datos que aún no estaban estructurados y escondían grandes hallazgos. Así, en una revista especializada, se describió a la “Data Science” como: “Todo lo que tiene algo que ver con la recopilación de datos y el análisis de modelos”. Sin embargo, esta definición no cubre el aspecto más importante que son las aplicaciones posibles, así como el “Machine Learning” o la “AI” por ejemplo.
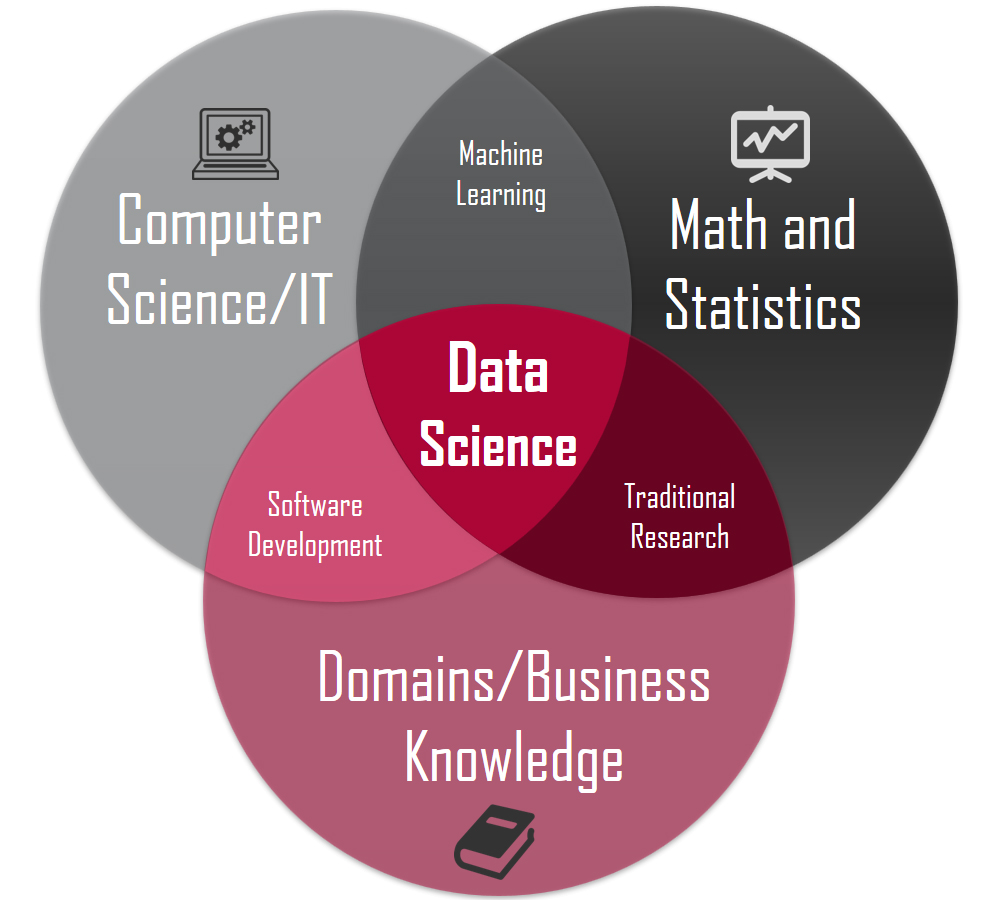 Así pues, en 2010 se hizo posible comenzar a entrenar máquinas con un enfoque basado en los datos, en lugar de con un enfoque basado en nuestro propio conocimiento. Todos los artículos teóricos sobre redes neuronales recurrentes soportan máquinas vectoriales, convirtiéndose en algo factible que puede cambiar la forma en que vivimos y experimentamos las cosas en el mundo. El “Deep learning” ya no es un concepto puramente académico, se convirtió en algo tangible y útil que afectaría nuestras vidas cotidianas, por lo que el “Machine Learning” y la inteligencia artificial (AI) han sido tema de conversación en los medios de manera predominante.
Así pues, en 2010 se hizo posible comenzar a entrenar máquinas con un enfoque basado en los datos, en lugar de con un enfoque basado en nuestro propio conocimiento. Todos los artículos teóricos sobre redes neuronales recurrentes soportan máquinas vectoriales, convirtiéndose en algo factible que puede cambiar la forma en que vivimos y experimentamos las cosas en el mundo. El “Deep learning” ya no es un concepto puramente académico, se convirtió en algo tangible y útil que afectaría nuestras vidas cotidianas, por lo que el “Machine Learning” y la inteligencia artificial (AI) han sido tema de conversación en los medios de manera predominante.
Otros aspectos sobre “Data Science”, como la experimentación, habilidades de exportación o análisis de datos, se han llamado tradicionalmente inteligencia comercial, por tanto, el público general ahora piensa en los profesionales de “Data Science” solo como investigadores enfocados en desarrollar técnicamente “Machine Learning” y “AI”, pero, por otro lado, la industria está contratando a estos profesionales como analistas.
 Entonces, hay una desalineación de expectativas ¿cierto? El motivo de esta discrepacia es que, si bien la mayoría de estos profesionales de “Data Science” probablemente puedan trabajar en problemas más técnicos, las grandes compañías como Google, Facebook o Netflix han tenido buenos resultados para mejorar sus productos y servicios gracias a los hallazgos y aportaciones de estos profesionales, aun sin el desarrollo de modelos técnicos complejos de años de desarrollo e investigación.
Entonces, hay una desalineación de expectativas ¿cierto? El motivo de esta discrepacia es que, si bien la mayoría de estos profesionales de “Data Science” probablemente puedan trabajar en problemas más técnicos, las grandes compañías como Google, Facebook o Netflix han tenido buenos resultados para mejorar sus productos y servicios gracias a los hallazgos y aportaciones de estos profesionales, aun sin el desarrollo de modelos técnicos complejos de años de desarrollo e investigación.
En vista de lo anterior, un buen profesional de “Data Science” no es aquel que trabaja con los modelos más avanzados o complejos posibles, sino aquel que logra un mayor impacto real de su trabajo; no es solo un analista de datos, es un solucionador de problemas.